Using AI to turn Youtube videos into Karaoke

TLDR; I created a CLI tool that converts any Youtube video it into a karaoke sing-along. See results at bottom here.
The Problem
One of the highlights of my year is when my friends and I make our way to NYC for Friendsgiving. We gather together to enjoy a Thanksgiving feast, catch up on each other’s lives, and cap off the night at Sing Sing, a popular karaoke bar in the East Village. We rent a private room and take turns belting our favorite tunes.
Due to licensing issues, each song you can chose has an instrumental recreation of the original. Each of these recreations sound a bit different from what you would normally listen to. Since each song must be recreated, the karaoke software only carries the most popular songs.
Year after year, I’ve wanted to sing “Parked out by the Lake” By Dean Summerwind, a personal favorite with deeply moving lyrics I know my friends would appreciate. But each time, I’m left disappointed when the song isn’t available. With no musical ability, I searched for a way to make an instrumental and karaoke video. It occurred to me that there might be a way to do this with AI.
The Plan
I stumbled across a fork of OpenAI’s Whisper on Github called WhisperX. It extends the Whisper functionality by automatically removing silent parts of audio, and uses a phoneme-based model to recognize the smallest unit of speech, e.g. the element p in “tap”. The output of WhisperX will give you timestamps of every character spoken in audio — perfect for karaoke. If I could find an instrumental and acapella track of “Parked out by the Lake”, I knew we were in business.
Luckily for me, Meta released Demucs, an incredible audio separater. You give it a song, and Demucs automatically extracts the vocals and backing tracks. Each time I use this tool, it feels like magic.
The plan started to unfold: if I could use Demucs to separate the vocals from instrumental, I could feed the vocals into WhisperX for transcription, then recombine them at the end with a transcription to form a karaoke video with ffmpeg. Better yet, if I could get audio from Youtube, I could easily turn any song into a karaoke video.

Code
Standing on the shoulder of giants (Demucs, WhisperX), the code is straight forward. You can find the full code here, including a notebook to try for yourself.
First we’ll get audio for a Youtube video
yt_url = "https://www.youtube.com/watch?v=D_zS_uiPWxs"
yt_id = yt_url.split("v=")[-1]
ydl_opts = {
"outtmpl": os.path.join(temp_dir, "%(id)s.%(ext)s"),
"quiet": True,
"verbose": False,
"format": "mp3/bestaudio/best",
"postprocessors": [{"key": "FFmpegExtractAudio", "preferredcodec": "mp3"}],
}
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
ydl.download([yt_url])
Then we need to separate the vocals and instrumental with Demucs. We’ll use a subprocess since Demucs is distributed as a CLI.
separated_path = os.path.join(temp_dir, "separated")
mp3_path = os.path.join(temp_dir, f"{yt_id}.mp3")
cmd = [
"demucs", "--two-stems=vocals",
f"--out={separated_path}",
f"{mp3_path}",
]
result = subprocess.run(cmd, encoding="utf8", capture_output=True, text=True)
Next we’ll transcribe the audio with WhisperX (you’ll want to use cuda for faster results)
audio_file_path = f"{separated_path}/htdemucs/{yt_id}/vocals.wav"
model = whisper.load_model("base", "cpu")
result = model.transcribe(audio_file_path)
model_a, metadata = whisperx.load_align_model(language_code=result["language"], device="cpu", model_name="WAV2VEC2_ASR_BASE_960H")
transcript = whisperx.align(result["segments"], model_a, metadata, audio_file_path, "cpu")
With the transcript from WhisperX, we can start to build whats called an .ASS file (yes you read that right). ASS stands for “Advanced Substation Alpha” and is commonly used with a tool called Aegisub. Basically, it’s a very capable subtitle editor.
Typically with transcription formats like SRT, you annotate sentence by sentence of what audio is playing. This works well for captioning, but in karaoke, it’s important to know what words and characters you should be singing. ASS provides a markup language where you can highlight character by character what’s on the screen. Here’s what that looks like in Aegisub
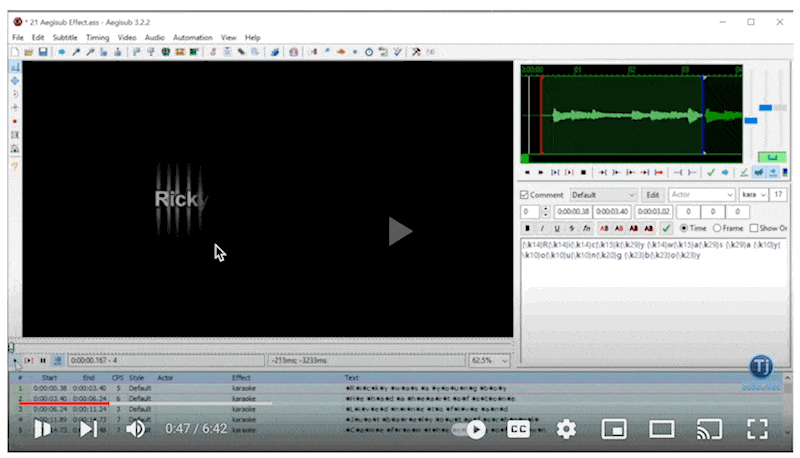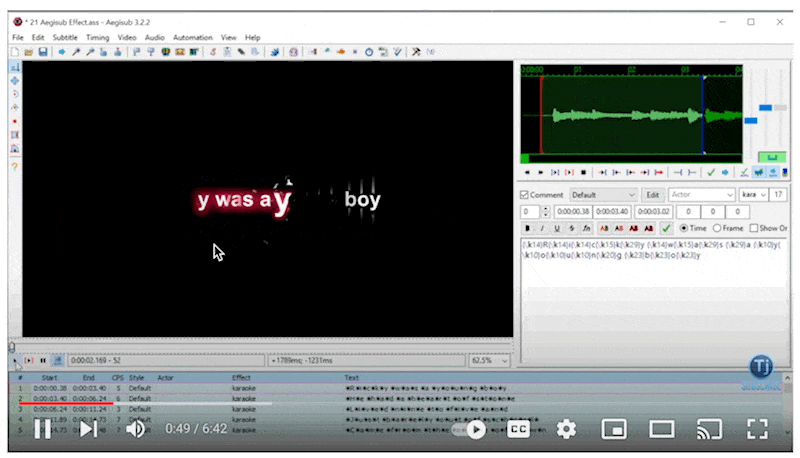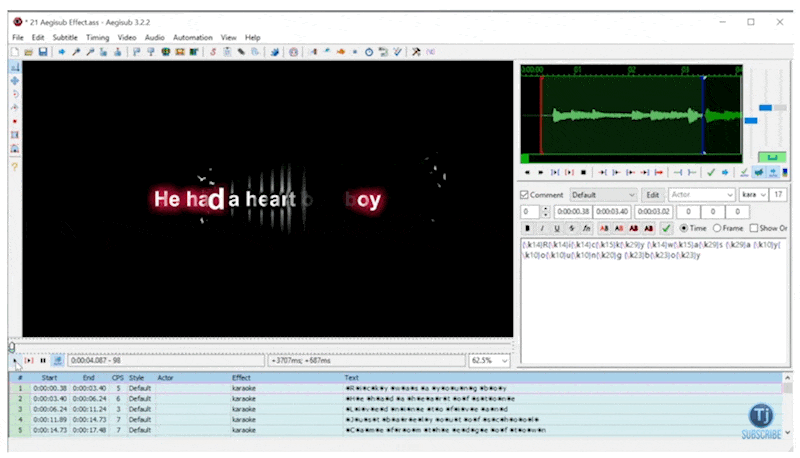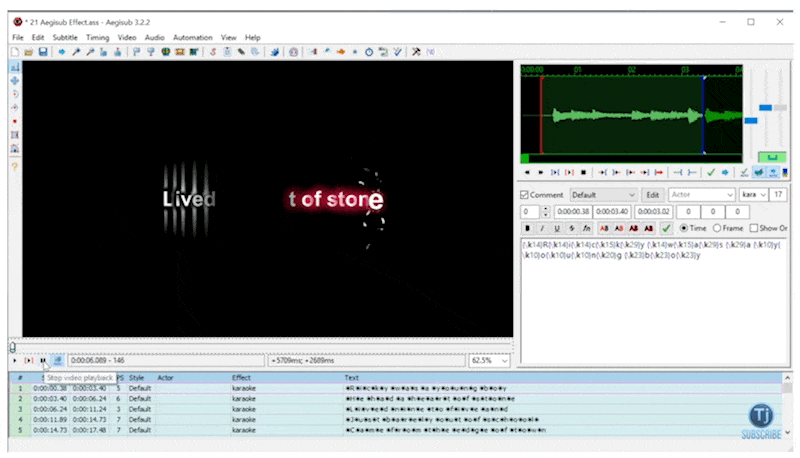
Using the ASS language, we can turn that WhisperX transcription into karaoke
template = """[Script Info]
ScriptType: v4.00+
PlayResX: 384
PlayResY: 288
ScaledBorderAndShadow: yes
[V4+ Styles]
Format: Name, Fontname, Fontsize, PrimaryColour, SecondaryColour, OutlineColour, BackColour, Bold, Italic, Underline, StrikeOut, ScaleX, ScaleY, Spacing, Angle, BorderStyle, Outline, Shadow, Alignment, MarginL, MarginR, MarginV, Encoding
Style: Default,Arial,20,&H00FFFFFF,&H000000FF,&H00000000,&H00000000,0,0,0,0,100,100,0,0,1,2,2,2,10,10,10,1
[Events]
Format: Layer, Start, End, Style, Name, MarginL, MarginR, MarginV, Effect, Text
"""
def secs_to_hhmmss(secs):
mm, ss = divmod(secs, 60)
hh, mm = divmod(mm, 60)
return f"{hh:0>1.0f}:{mm:0>2.0f}:{ss:0>2.2f}"
# See http://www.tcax.org/docs/ass-specs.htm
def generate_dialogue(transcript):
lines = []
for segment in transcript["segments"]:
chars = []
for cidx, crow in segment["char-segments"].iterrows():
if (
np.isnan(crow["start"]) and crow["char"] == " "
): # usually the first row is empty
continue
if np.isnan(crow["start"]):
length = "0"
else:
length = str(round(((crow["end"]) - crow["start"]) * 100))
chars.append("{\\k" + length + "}" + crow["char"])
line = f"Dialogue: 0,{secs_to_hhmmss(segment['start'])},{secs_to_hhmmss(segment['end'])},Default,,0,0,0,,{''.join(chars)}"
lines.append(line)
return "\n".join(lines)
def write_ass_file(transcript, path):
with open(path, "w") as f:
f.write(f"{template}\n{generate_dialogue(transcript)}")
subtitles_path = os.path.join(temp_dir, f"{yt_id}.ass")
write_ass_file(transcript, subtitles_path)
Now that the audio is separated, the transcription and ass file generated, we can fold it all back together with ffmpeg by calculating the new duration of the video.
instrumental_path = f"{separated_path}/htdemucs/{yt_id}/no_vocals.wav"
# Get the duration of the instrumental
with wave.open(instrumental_path, "r") as f:
frames = f.getnframes()
rate = f.getframerate()
duration = round(frames / float(rate), 2)
cmd = [
"ffmpeg", "-y", "-f", "lavfi", "-i",
f"color=size=1280x720:duration={duration}:rate=24:color=black",
"-i", instrumental_path, "-vf", f"ass={subtitles_path}",
"-shortest", "-c:v", "libx264", "-c:a", "aac",
"-b:a", "192k", "karaoke.mp4",
]
result = subprocess.run(cmd, encoding="utf8", capture_output=True, text=True)
Results
We now have a working program that takes any Youtube video and automatically converts into a karaoke sing-along video! I’ve also included some other examples.
Parked Out by the Lake
Subtitles start at 0:12
All Star - Smash Mouth
Great transcription, separation, and character alignment
God’s Plan - Drake
Not the best instrumental separation by Demucs or transcription by Whisper, but adlibs are picked up correctly.